Image classification via transfer learning—fast.ai lesson 1 and 2
Is your webcam pointed at art/text/plant
Notes on the lessons
Heartening
- The fast.ai libraries are very much batteries-included!
- Oversight of the existing data is discussed and important
- There is an abundance of models trained on Imagenet data
- Transfer learning feels like ✨fast✨ ✨magic✨ and is highly motivational
The motivating example in the notebook (the OxfordIIIT Pet Dataset) comes from a paper with 60% accuracy, and we can get more than 4x better in 8 years, with almost all the code wrapped up in libraries
- Widgets for data cleaning seems super useful (I know I have built simulacra of this many times before)
- nice to see CPUs sufficient for some kinds of inference (but GPUs much faster)
- the Jupyter animation (the y=ax+b stochastic gradient descent) seems useful!
- running hopskotch through cells in a notebook is extremely big Alan Perlis SICP preface energy
This book is dedicated, in respect and admiration, to the spirit that lives in the computer.
“I think that it’s extraordinarily important that we in computer science keep fun in computing. When it started out, it was an awful lot of fun. Of course, the paying customers got shafted every now and then, and after a while we began to take their complaints seriously. We began to feel as if we really were responsible for the successful, error-free perfect use of these machines. I don’t think we are. I think we’re responsible for stretching them, setting them off in new directions, and keeping fun in the house. I hope the field of computer science never loses its sense of fun. Above all, I hope we don’t become missionaries. Don’t feel as if you’re Bible salesmen. The world has too many of those already. What you know about computing other people will learn. Don’t feel as if the key to successful computing is only in your hands. What’s in your hands, I think and hope, is intelligence: the ability to see the machine as more than when you were first led up to it, that you can make it more.”
Alan J. Perlis (April 1, 1922-February 7, 1990)
Intriguing
- Very top-down: the guts of Resnet34/Resnet50 are not discussed (and there are multiple other drop-in replacements!)
- Pre-fab models download the trained weights and biases from ✨somewhere✨ on the internet (hence, an artifact repository like W&B) that maybe appreciates the traffic?
- Explicitly practical goals, versus “building a brain”
Surprising
- Parkhi et al just says that the animal images are from “people” from Catster and Dogster and Flickr and “Google Images” (cited as
http://images.google.com! how would Parkhi and Vedaldi and Zisserman and Jawahar feel about the Oxford-IIIT-Pet dataset be credited as “animal image datasets from the internet”, cited ashttp://bing.com?) - Continued curation of the data is unclear: what happens if I see a photo of my dog in there from ten years ago and want that removed?
- Transfer learning implies an “everything” model that gets refined to dozens of outputs. Do we know what isn’t in the model? If we foresake the model, how much longer does training take? A “view from nowhere” is a common ploy to avoid accountability (“accounts differ on the flatness of the Earth”)
- The license for the code and data seems pretty open-ended: even commercial GPS as a guidance system was limited to 1900 km/hr above 18 km and computer vision is even more powerful.
Deployment
Backend: via Render
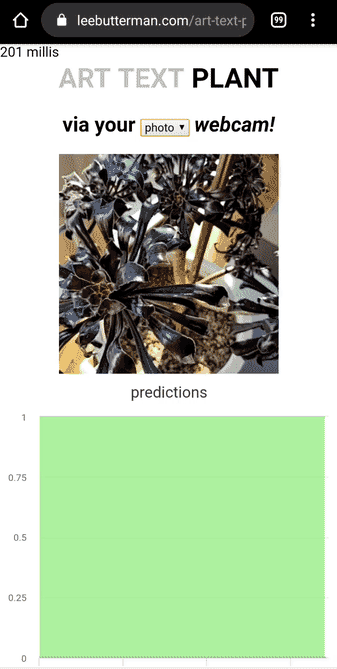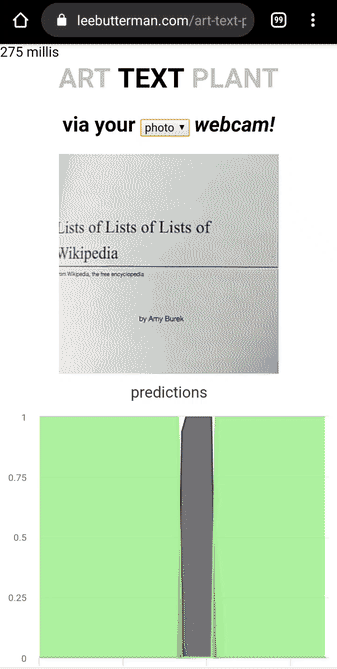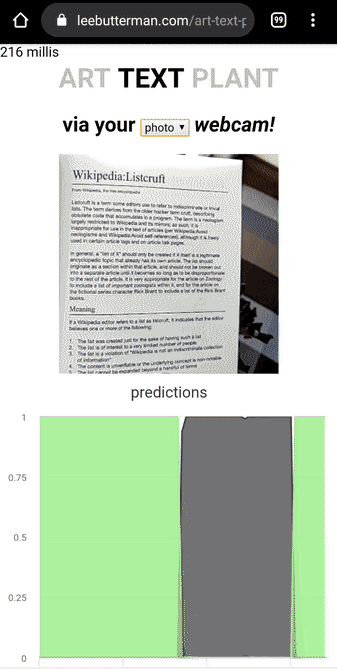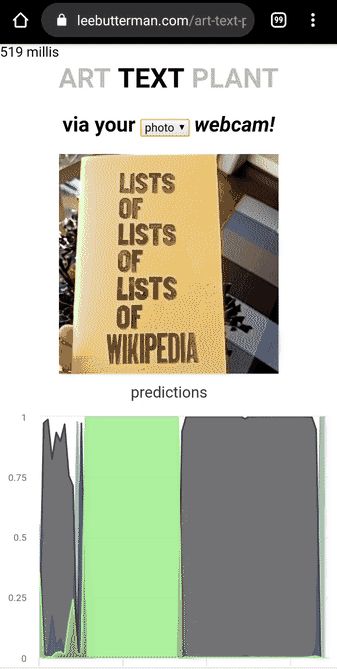
I took 8 photos of what I deemed “art” in my house, 7 photos of what I deemed “text” and 7 photos of what I deemed “plant”.

I trained a MobileNetV2 learner that could discern whether a supplied image was art or text or plant, and deployed it on Render.
Only a requirements.txt and an FastAPI app.py, with redeployments whenever I push to the art/text/plant repo, was super straightforward, and made development pretty joyful. Running the app on a local 8-core CPU I got latencies pretty consistently at 30ms (and on a 2018-grade GPU I got latencies under 10ms), but on the Render cloud I found that latencies much higher: in the animation at top, you can see the median latency are around 275 ms, and P99 latencies are over 3x P50 latencies.
Frontend: via React
The frontend was very straightforward with React: most of the heavy lifting came from react-webcam, and highcharts, and a little ring buffer. The frontend requests an animation frame, and when it gets the callback it latches closed, pulls an image from the webcam, sends it out for processing, hopes nothing goes wrong 🤞, measures the timing, ingests the response into its ring buffers to store the probability of an image being art or text or plant, plots the ring buffers, and adjusts the colors of ART / TEXT / PLANT based on what the camera seems to be pointing at.
Recording
Android screen recorder, and then ffmpeg (ffmpeg -i input.mp4 -map_metadata -1 -vf "fps=20,crop=in_w-0:in_h-90:0:65,scale=337:-1:flags=lanczos,split[s0][s1];[s0]palettegen=max_colors=37:reserve_transparent=false:stats_mode=single[p];[s1][p]paletteuse=dither=sierra2" -loop 0 output.gif) to turn it into an animated GIF: stripping the metadata, setting the frame rate to 20fps (each frame and its unique dithering is visible for 50ms, and the round-trip time for the image model is ~200ms), cropping the top of my phone’s UI, shrinking the video width in high quality, sending one stream of frames to generate a unique palette per frame (we have lots of orange at the end, lots of aeonium at the beginning, some floor rug at times), using another stream of frames with this generated palette with a high-quality dither for the output.
The indoor scene is relatively static, and the variations in dithering help establish a near-real-time frame rate, like the TikTok logo jittering.
Next up: image segmentation!